ML Model Governance with Model Cards and CI/CD on AWS
Introduction
Managing machine learning models at scale can be complex. Large companies often run tens or even hundreds of models at the same time, each with its own purpose, data dependencies, APIs and business owners. As the number of models grows, tracking metadata such as status, ownership or input/output schema becomes increasingly difficult. If no standardized process is set in place, teams risk duplication, dependency errors and reduced visibility into critical model governance information.
One possible way to solve this problem is to introduce model cards - a standardized markdown documentation format stored in each model’s GitHub repository. Each model card captures key metadata: description, inputs and outputs, status, team ownership, downstream APIs, dependencies, creation time, repository of the model’s codebase and others. To ensure discoverability, all model cards are published to a centralized static website hosted on Amazon S3. To automate validation and deployment, each repository is integrated with a GitHub Actions-based CI/CD pipeline that validates metadata against versioned schemas stored in AWS, then pushes changes to the S3-hosted site whenever a new model card is updated.
In this post, we’ll walk through this architecture and explain how AWS services simplify model governance, improve compliance and spread knowledge across teams on model metadata.
Model Cards as a Foundation for ML Governance
Machine learning governance starts with visibility. A model card is a simple markdown file, checked into the same repository as the ML model it describes, containing structured metadata, such as the following:
Status: Production, Staging, Deprecated
Description: Purpose of the model
Inputs/Outputs: Data schema
Team: Responsible group or owner
GitHub Repository: Where the code resides
Deployment Targets: APIs or applications using the model
Dependencies: Other models or services relied on
Timestamps: Creation date and update history
Experiment Data: Results from testing or monitoring
By standardizing this information across all model repositories, teams gain consistent visibility and reduce risks of misalignment. However, manually managing and validating model cards introduces overhead and can be error-prone, especially as the number of repositories and contributors grows. Different teams may interpret the schema differently, skip required metadata fields or introduce formatting inconsistencies that make aggregation into a centralized view difficult. Over time, these gaps can slow down audits, create confusion about model ownership and even block deployments when dependent services lack reliable metadata. This is where CI/CD comes in. By automating validation and deployment, organizations ensure that every model card remains accurate, compliant and immediately available to various stakeholders.
Automating Model Card Validation and Deployment with CI/CD
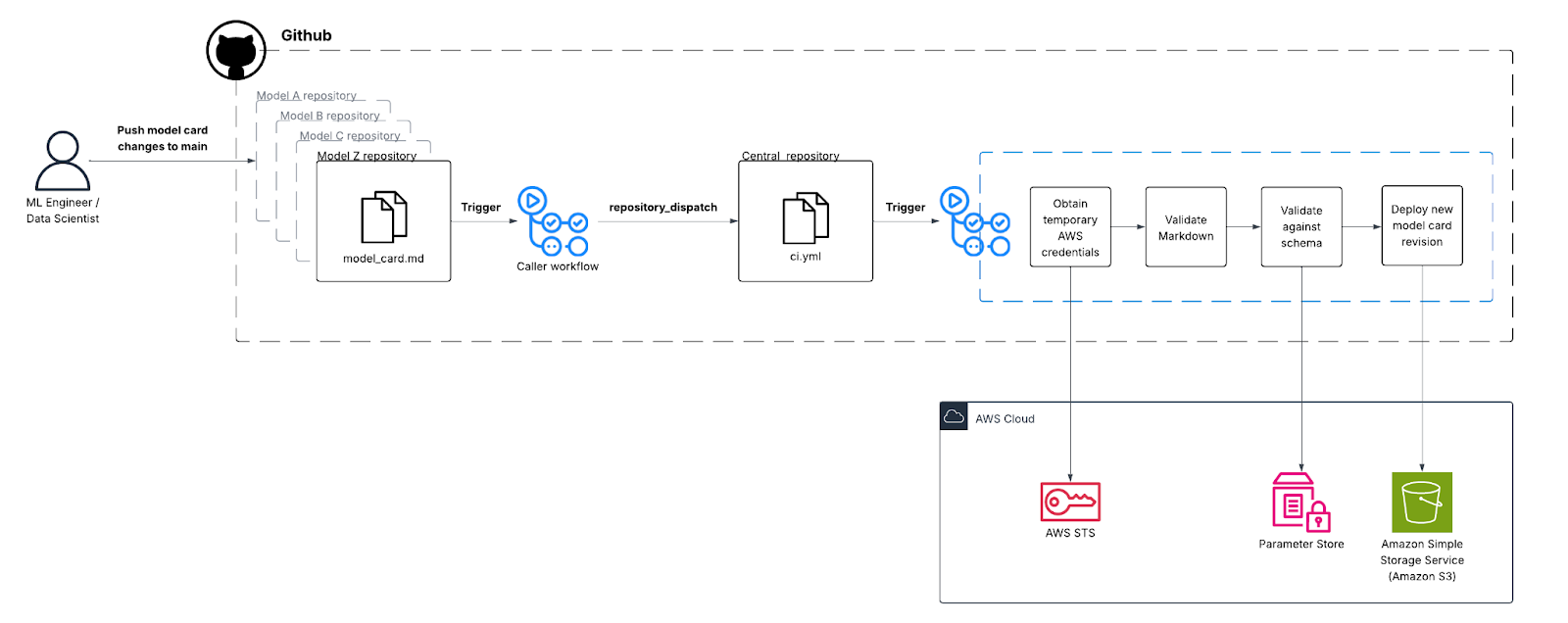
To bring automation into the model governance process, we designed a centralized CI/CD pipeline that validates, versions and deploys model cards whenever changes occur in any model repository. Instead of managing a separate validation workflow in every repository, we consolidated the process into a single “central pipeline” repository. This ensures consistency across teams and avoids duplication of automation logic.
The triggering mechanism works through GitHub’s repository_dispatch event [1]. Each model repository contains a lightweight workflow that listens for pushes to the main branch. When changes occur, this workflow doesn’t handle validation itself - instead, it securely calls the central pipeline repository and “dispatches” the work. This call is made with a repository_dispatch event that includes the source repository’s name as part of the payload. On the central side, a workflow configured to listen for repository_dispatch runs automatically, validating and deploying the updated model card.
The setup is straightforward. For example, in a source repository you define a small workflow that triggers on every push to main and then calls the GitHub API to send a repository_dispatch event against the central repository. This requires a Personal Access Token (PAT) stored as a GitHub secret. To make management easier at scale, especially across tens of repositories, organizations can use organizational secrets. By sharing the same PAT across multiple repositories, you simplify key rotation and avoid the overhead of maintaining individual tokens. The Github documentation states that: Organization secrets let you share secrets between multiple repositories, which reduces the need to create duplicate secrets. You can use access policies to control which repositories can use organization secrets [2]. The “caller” workflow could be fined as follows :
name: Trigger model card workflow
on:
push:
branches:
- main
jobs:
trigger:
runs-on: ubuntu-latest
steps:
- name: Trigger central pipeline
run: |
curl -X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${{ secrets.CI_PAT }}" \
https://api.github.com/repos/org/modelCardCentral-CI-Repo/dispatches \
-d '{"event_type":"modelcard-updated","client_payload":{"repo":"RepoA"}}'
There is also an official action maintained by Github in the marketplace for wrapping the above logic up and simplifying the pipeline code [3]:
jobs:
Dispatch:
runs-on: ubuntu-latest
permissions:
contents: write
steps:
- name: Repository Dispatch
uses: peter-evans/repository-dispatch@v3
with:
token: ${{ secrets.CI_PAT }}
repository: username/my-repo
event-type: modelcard-updated
client-payload: |-
{
"ref": "${{ github.ref }}",
"sha": "${{ github.sha }}",
"repo": "${{ github.repository }}"
}
When the event reaches the central pipeline repository, GitHub Actions spins up the main workflow. This workflow fetches the latest version of the model card schema from Amazon S3 or AWS Systems Manager Parameter Store (as both services support versioning), validates the updated markdown file against required fields such as status, description, inputs and outputs and checks formatting consistency. Github Actions’ access to AWS is controlled through AWS IAM and Github OIDC provider that allows the workflow to assume a specific role defined in IAM (based on the GitHub organization, repository and reference) [4]. If the validation succeeds, the model card is deployed to the internal static documentation portal on Amazon S3. By using versioned schemas stored in AWS, teams can track how validation rules evolve over time and audit old model cards against the standards that applied when they were first created. Amazon S3’s support for versioning allows model cards for the same model to be versioned as well. For larger organizations, adding Amazon CloudFront as a distribution layer provides global access, caching and additional security controls to the static website. The “callee” workflow can be integrated with the “caller” workflow as follows:
name: Model card central repository
on:
repository_dispatch:
types: [modelcard-updated]
jobs:
myEvent:
runs-on: ubuntu-latest
steps:
- name: Checkout caller repo
uses: actions/checkout@v3
with:
repository: ${{ github.event.client_payload.repo }}
ref: ${{ github.event.client_payload.ref }}
token: ${{ secrets.CI_PAT }}
- run: echo "Checked out commit ${{ github.event.client_payload.sha }} from ${{ github.event.client_payload.repo }}"
- run: echo “Retrieving the latest model card schema version from S3…”
…
One of the advantages of this approach is that it does not interfere with existing CI/CD pipelines already present in individual repositories. Teams can continue to run their model training, packaging or deployment workflows in the same repo-branch combination while the centralized pipeline focuses exclusively on model card validation and publishing. In other words, this pattern overlays governance automation without disrupting development pipelines already in place.
By centralizing governance logic in this way, companies could achieve consistency, scalability and auditability across all model repositories. Developers simply push model card changes to the main branch and the system ensures that every model card is validated, compliant and published without additional effort.
The following chart visually represents an example architecture of the end-to-end pipeline:
Hosting the Model Card Portal on Amazon S3
Once validated, all model cards are published to an internal portal that unifies documentation in a single location. This portal, hosted on Amazon S3, provides cost-effective and highly durable storage for the static pages that display each model’s metadata. To ensure a smooth experience for globally distributed teams, the site is fronted by Amazon CloudFront, which accelerates content delivery through edge caching and reduces latency. Access to the portal could be tightly secured using a company-wide OIDC identity provider, so only authorized entities can view the models’ metadata [5]. The deployment process itself is fully automated: the same GitHub Actions pipeline that validates model cards also uploads the approved files directly into the S3 bucket using the AWS CLI or SDK. With this design, the organization creates a single, authoritative source of truth for machine learning model documentation, ensuring that engineers, product managers and other stakeholders always have a reliable and up-to-date view of the models in production.
What This Means for You
By introducing model cards and automating their validation through a centralized CI/CD pipeline, you gain a practical way to balance speed with governance. For developers, this means less overhead and fewer manual steps - updates to documentation happen as part of the same workflow where you already manage code, with the assurance that every change is automatically validated against your organization’s latest standards. Perhaps most importantly, centralizing validated model cards into a single, browsable portal improves collaboration and discovery across teams. Instead of scattered documentation or inconsistent metadata, stakeholders get one source of truth that clearly shows ownership, dependencies and deployment status. Whether you are a data scientist looking for an input schema, a machine learning engineer maintaining dependencies or a compliance lead preparing for an audit, this solution strengthens transparency, reproducibility and operational excellence across the machine learning lifecycle.
Whether it’s GenAI, CI/CD, or cloud cost chaos - we’ve seen it before. Let’s walk through how we’ve solved it, and see if it fits your world.
References
[1] “Events that trigger workflows”, GitHub Docs, https://docs.github.com/en/actions/reference/workflows-and-actions/events-that-trigger-workflows#repository_dispatch
[2] “Managing development environment secrets for your repository or organization”, GitHub Docs, https://docs.github.com/en/codespaces/managing-codespaces-for-your-organization/managing-development-environment-secrets-for-your-repository-or-organization
[3] “Repository Dispatch”, GitHub Marketplace,
https://github.com/marketplace/actions/repository-dispatch
[4] “Configuring OpenID Connect in Amazon Web Services”, GitHub Docs,
https://docs.github.com/en/actions/how-tos/secure-your-work/security-harden-deployments/oidc-in-aws
[5] Viyoma Sachdeva and Matt Noyce, “Securing CloudFront Distributions using OpenID Connect and AWS Secrets Manager”, AWS Blogs, 09 Oct 2020,
Relevant Success Stories
.png)
.png)
Book a meeting
Ready to unlock more value from your cloud? Whether you're exploring a migration, optimizing costs, or building with AI—we're here to help. Book a free consultation with our team and let's find the right solution for your goals.