Accelerating Real-Time Fraud Detection with Amazon SageMaker AI Inference Pipelines
Fraud detection is one of those machine learning use cases where speed matters as much as accuracy. A model can be very good at spotting suspicious transactions, but if the full request takes too long to process, the result may arrive after the decision has already been made. That is a problem in real-time systems. By the time the score comes back, the payment may have cleared, the order may have shipped, or the account may already have been used in a risky way.
This is why fraud detection is not just about training an accurate model. It is also about building a fast and reliable inference path around the model. In many architectures, that path gets split across several services. One service prepares the features, another service calls the model, and another service handles the output. That can work, but it can also add latency, complexity, and more moving parts to operate.
Amazon SageMaker AI Inference Pipelines are a strong fit for that kind of design. They let you chain preprocessing, prediction, and post-processing into one managed model flow. In this post, we will look at what inference pipelines are, why they matter for real-time fraud detection, and how an XGBoost-based fraud system can use them to stay fast, reliable, and easier to operate.
One Request In, One Decision Out
An inference pipeline defines how a single request is processed from start to finish. A request enters the system, passes through a series of containers, and leaves as a decision or score. In Amazon SageMaker AI, an inference pipeline is a sequence of two to fifteen containers that process inference requests. The pipeline can include SageMaker AI built-in algorithms, custom algorithms packaged in Docker containers, or a mix of both. The full pipeline behaves like one SageMaker AI model, even though several steps may happen inside it [1].
That matters because fraud detection usually needs more than a raw model call. The incoming data often needs cleanup, normalization, feature engineering, or conversion into the format the model expects. The model then generates a score or class prediction. After that, the system may need to convert the output into a business-friendly result, such as a fraud risk label, a confidence score, or a threshold-based decision.
If those steps happen in separate services, every extra hop can introduce more latency and more failure points. When they happen inside a pipeline, the steps stay together in one managed flow. SageMaker AI installs and runs the containers on the same Amazon EC2 instances that back the endpoint or batch transform job, which helps keep feature processing and inference close to the compute that is serving the request [1]. For a real-time fraud system, that co-location is a practical advantage because it helps reduce delay at the exact moment when a fast answer matters most.
Why Fraud Detection Is a Good Fit for Inference Pipelines
Fraud detection is not a generic prediction task. It is a decision system that often sits on the path of a live transaction. The system has to be quick enough to support a real-time response. It has to be accurate enough to avoid blocking good users. And it has to be maintainable enough that the team can update it as fraud patterns change.
This is where Sagemaker AI Inference Pipelines make sense. They let you keep the logic for feature preparation, scoring, and output shaping in one place without forcing you to build a separate orchestration layer just for inference. That reduces the distance between the data entering the system and the model making the decision. It also keeps the deployment model cleaner. Instead of managing three or four endpoints and multiple service contracts, you can treat the whole flow as one endpoint-backed model.
Fraud detection also tends to depend on feature transformations that are easy to describe but challenging to maintain as separate microservices. A transaction amount may need scaling. A timestamp may need to be converted into a time-of-day feature. A merchant category may need encoding. A user or device attribute may need to be mapped into a form that the model can use. These transformations are not the business outcome themselves. They are supporting steps, and inference pipelines are a good way to keep them close to the model instead of scattering them across the system.
That is especially useful when the model and the transformations change together. If the training pipeline creates features one way, the inference path should mirror that same logic as closely as possible. The inference pipeline helps keep training and serving consistent by allowing you to reuse the same feature transformation logic and algorithms in both stages. This reduces the risk of differences between how data is prepared during training and how it is handled in production, which is a common cause of the “training-serving skew” problem and can lead to unreliable model performance over time [2].
How is the Inference Pipeline Constructed
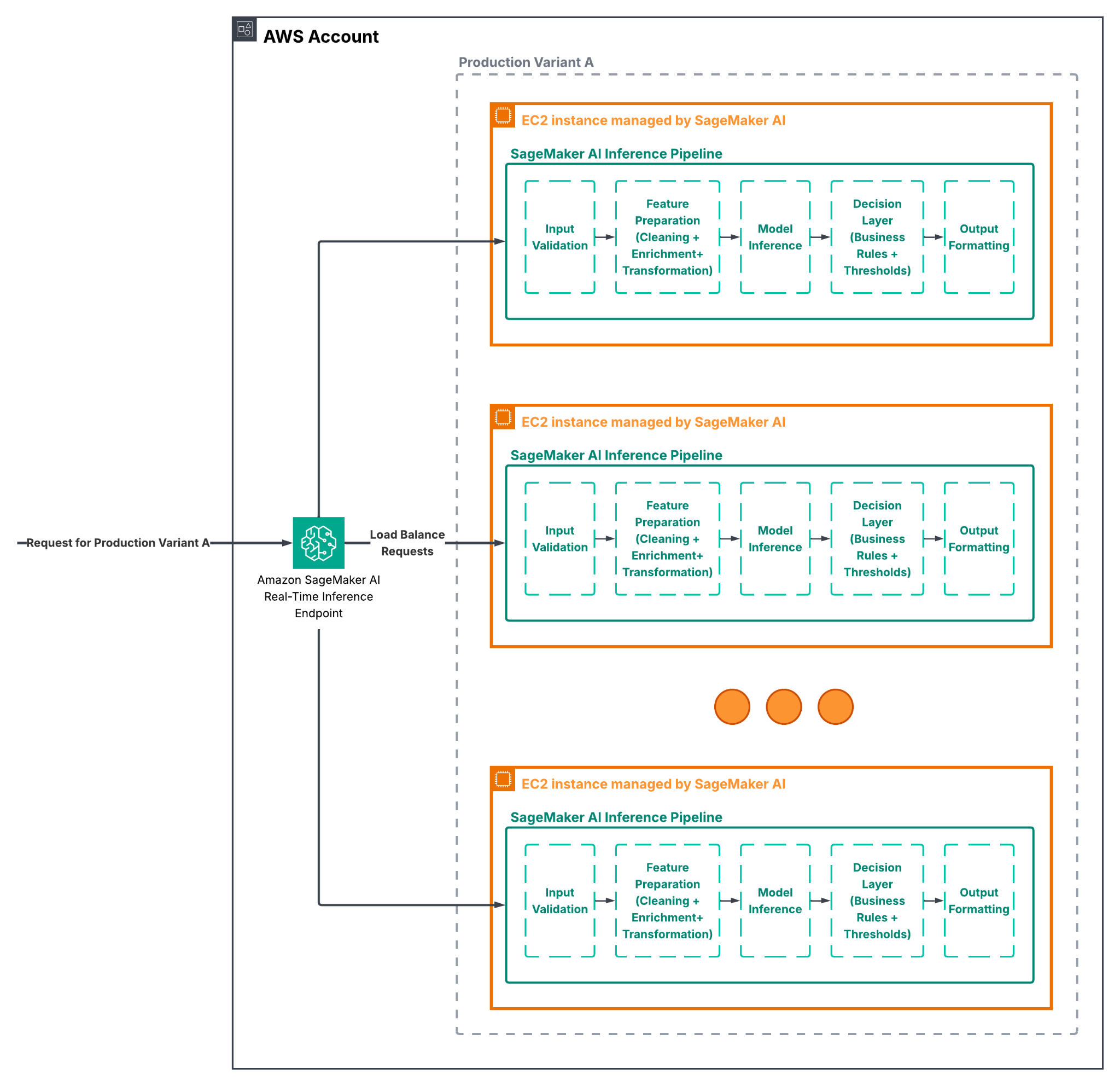
Figure 1. “SageMaker AI Inference Pipeline Sample Architecture”
As already mentioned, SageMaker AI inference pipeline is a chain of containers that run in order. The first container often handles preprocessing. The middle container is usually the model itself. The last container may post-process the output into a more useful format. In a fraud system, that might mean a preprocessing container that builds features from raw transaction data, an XGBoost container that produces a risk score, and a post-processing container that turns the score into a decision such as approve, review, or block, before sending it to a downstream system.
This flexibility is one of the main reasons organizations choose this approach. As previously mentioned, you can use SageMaker AI built-in algorithms, custom training and inference code in containers, or pre-built framework containers. That means the pipeline can be simple when the use case is simple, or more customized when the fraud logic is specific to your domain. You are not locked into a single style of model or a single style of preprocessing. This also means the pipeline can support both real-time inference and batch transform [1]. The same assembled inference pipeline can be used as a SageMaker AI model for online prediction or for batch processing a large dataset. In a fraud context, that gives teams room to reuse the same logic for different tasks. Real-time scoring may be used for live card payments, while batch transform may be used for scoring historical transactions, investigations, or additional model validation. That consistency matters. When a system uses one set of transformations for online inference and a different set for batch analysis, teams spend time reconciling results. A pipeline reduces that drift because the same model assembly can be used across both modes.
The Fraud Detection Story: Why the Architecture Matters
Imagine a payment platform that needs to score every transaction in real time. The incoming request includes details such as transaction amount, merchant type, customer history, device signals, geolocation, and perhaps a few derived features from previous activity. Some of those values come directly from the request. Some come from feature stores, databases, or recent event history. Some need to be transformed before they can be used by the model.
Now imagine building that system as separate microservices. One service collects the features, another service prepares them. Then another service calls the model and a final service interprets the score and makes the final decision. That may sound modular, but it also creates more network calls, more version coordination, more places for latency to build up, and more chances for one step to drift away from another. If one service slows down, the whole decision path slows down.
With an inference pipeline, the critical steps live together. The request enters the endpoint and flows through the containers in order. The transformation code and the model code are deployed together. The whole chain is fully managed together. That does not remove the need for good engineering, but it does simplify the shape of the problem. For a fraud system, that is a real benefit because the system’s most important goal is to make a fast and reliable decision in a short time window.
Another reason this design fits fraud detection is operational clarity. Fraud systems are often monitored closely because they directly affect revenue, customer experience, and risk exposure. If the pipeline is the main inference path, it becomes easier to reason about latency, trace failure points, and monitor response behavior. You can observe the pipeline as a single service boundary instead of trying to understand how requests move between several endpoints. This also makes it easier to explain decisions to stakeholders, as the full path from input to approval or denial is clearly defined and easy to trace within a single flow.
A Simple Example of the Pipeline Structure
The code below shows the shape of a real-time inference pipeline in SageMaker AI. The exact preprocessing and post-processing logic will vary by project, but the idea is the same: build the containers, chain them together, and deploy them as one model.
from sagemaker.sklearn.model import SKLearnModel
from sagemaker.xgboost.model import XGBoostModel
from sagemaker.pipeline import PipelineModel
import sagemaker
session = sagemaker.Session()
# 1. Preprocessing
preprocess_model = SKLearnModel(
model_data=preprocess_model_data,
role=role,
entry_point="preprocess.py",
framework_version="1.2-1",
sagemaker_session=session
)
# 2. Inference (XGBoost)
xgboost_model = XGBoostModel(
model_data=xgboost_model_data,
role=role,
entry_point="inference.py",
framework_version="1.7-1",
sagemaker_session=session
)
# 3. Postprocessing
postprocess_model = SKLearnModel(
model_data=postprocess_model_data,
role=role,
entry_point="postprocess.py",
framework_version="1.2-1",
sagemaker_session=session
)
# 4. Pipeline Construction
pipeline_model = PipelineModel(
name="fraud-detection-pipeline-v1",
models=[preprocess_model, xgboost_model, postprocess_model],
role=role,
sagemaker_session=session
)
# 5. Deployment
predictor = pipeline_model.deploy(
initial_instance_count=1,
instance_type="ml.m5.large"
)
This style of deployment makes the flow easier to understand. There is one deployed artifact, but inside it are the steps that matter to the decision. A common pattern in the preprocessing stage is to keep the logic simple and deterministic. That might mean using scikit-learn or Apache Spark code to clean and shape the data. SageMaker AI supports custom transformation logic inside the pipeline, so you do not need a separate service just to prepare the input. The goal is not to move every possible step into the pipeline for its own sake. The goal is to keep the steps that belong to inference close to the inference endpoint [3].
Why Not Split All Components into Separate Microservices
Microservices are useful when a system needs clear domain boundaries, independent scaling, or separate deployment cycles. But inference might not always be the best place to split components apart, especially in time-sensitive use cases. In fraud detection, the preprocessing and prediction steps are tightly connected. They are often part of the same decision path and should change together when the model changes.
If you split them into separate services, you gain some independence, but you also introduce extra network hops and more integration work. You may have to manage service discovery, retry behavior, version alignment, and cross-service latency. That can make the system more fragile than it needs to be. When the end-to-end path is already time-sensitive, every small delay matters. An inference pipeline keeps the architecture simpler where it counts. The containers are still separate from a code perspective, so you can keep each responsibility clean, but they are deployed together, scaled together, and observed together as one model. That is a good middle ground and often a beneficial trade-off between monolithic code and a fully distributed serving stack. There is also the question of consistency. In fraud detection, if preprocessing is done externally, there is a risk that training-time feature logic and serving-time feature logic diverge. That may happen slowly over time, and it is often hard to catch until performance drops. A pipeline makes it easier to keep the logic together and reduce that risk.
Monitoring the Pipeline in Real Time
Monitoring is a critical part of any machine learning system, not just fraud detection. Models operate in dynamic environments where data patterns, traffic, and system behavior can significantly drift over time. When model performance shifts or latency starts to increase, operational teams need to detect those changes early and understand what is happening in production. Without proper visibility, even a well-performing model can become unreliable without clear signals as to why.
Amazon SageMaker AI integrates with Amazon CloudWatch to provide that visibility across inference pipelines. CloudWatch collects logs and metrics from each stage of the pipeline and turns them into near real-time insights, making it easier to understand how requests are being processed end-to-end. This allows you to track latency, monitor error rates, and observe how the system behaves under different loads, all within a unified monitoring layer [4].
This level of observability is important both for troubleshooting and for long-term system health. When something goes wrong, logs can help identify which step in the pipeline caused the issue, whether it is a preprocessing error, a model failure, or unexpected output. Over time, these metrics also help teams spot trends, such as gradual increases in latency or changes in response patterns, which may indicate deeper issues with the model or the data.
In real-time use cases like fraud detection, this becomes even more important. As input data and user behavior change, the system must continue to make accurate decisions without slowing down. Monitoring through CloudWatch allows you to react early, maintain performance, and ensure that both the model and the surrounding pipeline continue to operate as expected in a production environment.
A Better Shape for a Real Fraud System
What makes SageMaker AI Inference Pipelines valuable is not just the technology itself, but how well it fits the problem you are trying to solve. Fraud detection is inherently a multi-step decision process. The system needs to take raw transaction data, transform it into a model-ready format, generate a score quickly, and translate that score into a clear action. These steps are closely connected and, in practice, work best when they are treated as parts of the same flow rather than separate systems.
Inference pipelines provide a way to keep that flow unified without losing clarity in responsibilities. Each stage can still focus on doing one thing well. The preprocessing step handles feature transformation, the XGBoost model focuses on scoring, and the post-processing step applies the final business logic. At the same time, everything is deployed and executed as a single unit, which simplifies how the system is managed and how requests are handled end-to-end.
That balance is what makes this architecture effective. It is not about pushing every piece of logic into SageMaker AI, but about bringing together the parts of the inference path that naturally belong together. For real-time systems like fraud detection, this leads to a design that is easier to operate, easier to reason about, and better aligned with how decisions are actually made in production.
What This Means for You
Inference pipelines bring benefits across different parts of a team, and those benefits tend to reinforce each other in real-world systems. For product teams, they make fraud detection systems faster to ship and easier to explain, since the full decision flow lives in one managed model instead of being spread across multiple services. That same structure also helps data science teams keep preprocessing aligned with the model, which is critical in fraud detection where even small inconsistencies in feature handling can affect performance. When the transformation logic sits alongside the model, it becomes much easier to ensure that training and serving behave the same way.
At the same time, platform and operations teams benefit from a simpler runtime setup. There are fewer services to coordinate, fewer endpoints to manage, and a clearer place to monitor latency, errors, and overall system behavior through tools like CloudWatch. Instead of piecing together signals from multiple components, the pipeline provides a more unified view of how requests are processed end-to-end.
In a real-time fraud detection system, these advantages come together in a practical way. The result is a system that can score transactions with low latency, keep the decision logic centralized, and remain easier to maintain as fraud and data patterns change over time.
What’s Next
Fraud detection will always demand a combination of speed, accuracy, and operational clarity. Amazon SageMaker AI Inference Pipelines are a strong option when you want preprocessing, prediction, and post-processing to work as one flow instead of as separate parts of a larger distributed system.
If your team is building a real-time fraud detection platform, this architecture is worth considering early. It helps keep the serving path compact, keeps the model logic close to the feature logic, and gives you a cleaner way to monitor and maintain the system over time.
We are just getting started with this topic. If you want to explore how SageMaker AI Inference Pipelines could fit your own fraud detection workflow, or how to design the preprocessing and scoring stages around a real-time endpoint, we would be happy to help. Let’s look at how SageMaker AI Inference Pipelines can fit your system and help you make faster decisions with less operational friction.
References
[1] “Inference pipelines in Amazon SageMaker AI”, AWS Docs,
https://docs.aws.amazon.com/sagemaker/latest/dg/inference-pipelines.html
[2] Megha Natarajan, “What is Training-Serving Skew, and how can it be prevented on Google Cloud Platform?”, Medium, 10 Nov 2023,
[3] “Run Real-time Predictions with an Inference Pipeline”, AWS Docs,
https://docs.aws.amazon.com/sagemaker/latest/dg/inference-pipeline-real-time.html
[4] “Inference Pipeline Logs and Metrics”, AWS Docs,
https://docs.aws.amazon.com/sagemaker/latest/dg/inference-pipeline-logs-metrics.html
Relevant Success Stories
.png)
.png)
Book a meeting
Ready to unlock more value from your cloud? Whether you're exploring a migration, optimizing costs, or building with AI—we're here to help. Book a free consultation with our team and let's find the right solution for your goals.